Сервисы и ИИ модели для генерации устной речи для бизнеса
Обновлено: 02.06.2026
Технологии машинного обучения позволяют синтезировать человеческую речь, не прибегая к услугам студий озвучки. Синтез речи применяется для бизнеса в следующих приложениях:
- персональные голосовые ассистенты
- голосовое меню IVR
- создание видеороликов
- системы автообзвона
- call-центры
Примеры использования синтеза речи для бизнеса с помощью искусственного интеллекта приведены ниже.
- персональные голосовые ассистенты
- голосовое меню IVR
- создание видеороликов
- системы автообзвона
- call-центры
Примеры использования синтеза речи для бизнеса с помощью искусственного интеллекта приведены ниже.
2026. Microsoft представила AI модели для генерации и распознавания речи
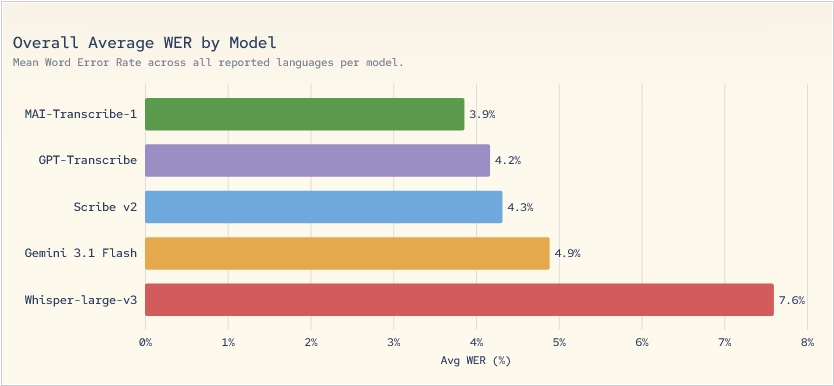
Microsoft продолжает развивать собственные AI-модели MAI (чтоб поддерживать независимость от партнерского OpenAI). Новая модель MAI-Transcribe-1 для преобразования речи в текст, по данным компании, показывает лучшую точность на бенчмарке FLEURS для 25 наиболее используемых языков и работает в 2,5 раза быстрее предыдущего решения Azure Fast. В Microsoft заявляют, что модель оптимизирована для реальных условий — с шумом и нестабильным звуком. Вторая новая модель, MAI–Voice-1 предназначена для генерации речи. Она способна создавать до 60 секунд аудио всего за одну секунду, сохраняя интонации и особенности голоса. Также разработчики добавили возможность создавать собственный голос на основе нескольких секунд записи, что упрощает создание голосовых интерфейсов и ИИ-агентов.
2024. В блокноте Google NotebookLM появились AI-аудиосводки

Google добавил функцию создания аудио-саммари в своём AI-блокноте NotebookLM. Эта функция позволяет генерировать что-то типа подкастов на основе контента, которым делятся пользователи. Это помогает пользователям легче воспринимать и усваивать информацию из длинных документов или видео. Так как разговоры могут касаться неважных вопросов, функция позволяет настраивать пересказы в зависимости от нужд пользователя, делая аудио более сфокусированным на конкретных темах внутри контента.
2023. ChatGPT получил возможность синтеза речи и понимания изображений
OpenAI анонсировала важное обновление для ChatGPT — теперь генеративные модели GPT-3,5 и GPT-4 могут анализировать изображения и реагировать на них так же, как на текстовое общение. Вдобавок, мобильное приложение ChatGPT добавит функцию синтеза речи, которая вместе с уже имеющейся функцией распознавания речи обеспечит возможность вести полноценные устные беседы с чатботом. В основе функции синтеза речи лежит «новая модель преобразования текста в речь». Пользователь может выбрать один из вариантов голосов, которым будет говорить чатбот. Все они были созданы при участии профессиональных актеров озвучивания. OpenAI планирует предоставить все эти функции ChatGPT для пользователей подписки Plus и Enterprise «в ближайшие две недели». Синтез речи будет доступен только для устройств с iOS и Android, а распознавание изображений — в мобильных приложениях и в веб-интерфейсе.
2023. ИИ от Microsoft имитирует любой голос на основе трехсекундной записи
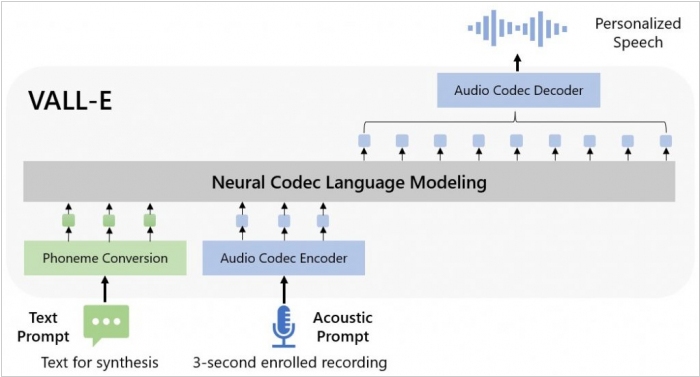
Microsoft представила искусственный интеллект, который может воспроизвести любой голос, передавая эмоции и тон говорящего. Компания Microsoft представили искусственный интеллект VALL-E. Он может генерировать голосовые записи на основе трехсекундного образца. Исследование показало, что модель, обученная на основе множества коротких отрывков, генерирует английскую речь, которую невозможно отличить от голоса оригинала. Анализ показал, что системе достаточно трехсекундного ролика для имитации голоса собеседника. При этом Vall-E значительно превосходит современную систему TTS с точки зрения естественности звучания речи и сходства голоса. Кроме того, она может сохранять эмоции говорящего и акустическую среду (влияние акустических свойств помещения, в котором была сделана оригинальная запись).
2022. Microsoft закрывает доступ к своим ИИ-разработкам распознавания лиц и генерации голоса
Microsoft опубликовала документ под названием «Стандарт ответственного использования ИИ», в котором указывается, что Microsoft приложит все усилия для минимизации возможного вреда от инструментов машинного обучения. Для этого вводятся более жесткие правила использования инструментария, разработанного Microsoft. На практике это означает следующее: Microsoft ограничивает доступ к инструментарию в Azure, который позволяет создавать решения по распознаванию пола и возраста людей по их изображениям на основе Face API. На средства распознавания эмоций людей по их видео или фотографиям также вешается замок. Также, ограничения коснутся средств распознавания лиц в целом и генерации реалистичного звука голоса. Доступ к таким инструментам теперь будет осуществляться по предварительной заявке, и решение, предоставлять доступ или нет, будет зависеть от того, сочтут ли проект потенциально вредным.
2021. Microsoft и NVIDIA создали крупнейшую нейросеть для генерации языка
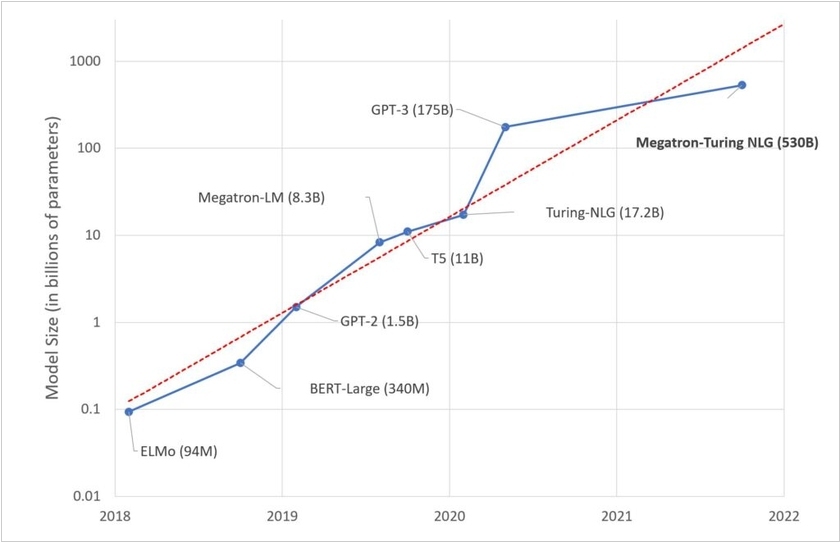
Microsoft и NVIDIA объединили усилия и создали крупнейшую на данный момент модель Megatron-Turing Natural Language Generation, способную понимать и генерировать человеческую речь. По словам разработчиков, модель продемонстрировала высокую точность в выполнении таких задач как понимание текста, определение смысла слова с несколькими значениями, завершение текста по смыслу, представление логических выводов и написание заключений в стиле, похожем на человеческий. Для обучения ИИ компании использовали суперкомпьютер, а также привлекли облачную систему. Благодаря этому, в ИИ за месяц удалось загрузить 1,5 Тб данных из разных баз.
2020. Сервис Synthesia создает видеообращения из произвольного текста
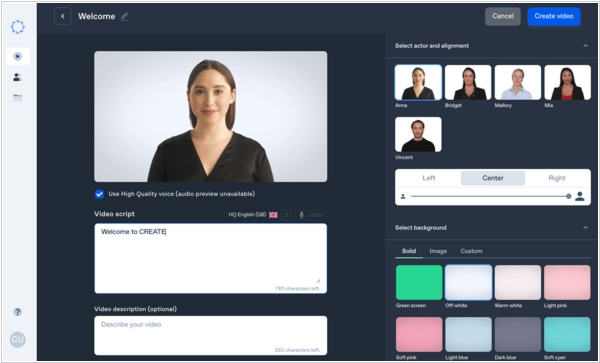
Онлайн платформа Synthesia позволяет преобразовать любой текст в видео, где его начитывает виртуальный персонаж. Чтобы воспользоваться новой функцией, введите свой текстовый сценарий и нажмите на кнопку «Генерировать». Видео будет готово через несколько минут, при стандартном объеме это займет 15 минут. Новая платформа доступна на 34 языках, в частности на русском. При стандартной генерации ваш текст читает актриса Анна, помимо нее можно выбрать из еще десяти персонажей. Создатели предлагают использовать новый сервис для организации рабочих презентаций, отправки видео-сообщений и других целей.
2020. Google добавила в мессенджер Google Duo функцию восполнения обрывков слов во время разговоров
Google улучшила качество аудиозвонков в Google Duo, используя систему WaveNetEQ с поддержкой технологий искусственного интеллекта. Обычно, из-за нестабильности интернет-соединения, во время беседы звук может искажаться и прерываться. WaveNetEQ — система PLC, которая реалистично синтезирует недостающие фрагменты живой речи. Работа WaveNetEQ основана на большом массиве речевых данных — записанных голосах 100 людей, говорящих на 48 языках. Технология анализирует речь, чтобы синтезировать продолжение звучания, если голос говорящего временно пропадёт. Когда передача речи восстанавливается, технология «соединяет» искусственный звук с настоящим. Система «обучена» распознавать речь в разной обстановке, с разным уровнем фонового шума.
2020. Google Assistant научился читать тексты вслух
На выставке CES Google продемонстрировал новую способность своего виртуального помощника Google Assistant - читать тексты вслух. Уже скоро (через пару месяцев) вы сможете открыть статью, новость или просто веб-страничку с контентом сказать "ок, гугл, прочитай это", и ассистент сам обнаружит текстовую часть и прочитает вслух (на любом из 42 языков, включая русский). Конечно, сервисы чтения текстов уже дано существуют, но в Google говорят, что у них получилось создать хорошую нейросеть для расстановки ударений и интонаций, так что качество будет выше. По крайней мере, судя по промо-ролику, английский текст звучит действительно качественно.
2017. Baidu представила систему преобразования текста в речь Deep Voice

Китайская компания Baidu представила систему преобразования текста в речь, которая называется Deep Voice. Она представляет собой нейросеть, созданную с помощью технологии глубокого обучения, в ходе которого она анализировала речь и сопоставляла её с текстом, после чего начала вполне сносно произносить слова. Сначала Deep Voice раскладывает слово на отдельные звуки, затем вводит данные в систему синтеза речи и произносит нужное слово. Несмотря на значительные успехи китайского поискового гиганта, компания Google продолжает лидировать в этой области. Её система WaveNet уже успешно синтезирует речь, опираясь на «прочитанный» ранее текст. Сейчас американская разработка умеет говорить на двух языках, и специалисты продолжают над ней работать.
2016. Google DeepMind научился говорить
Большинство популярных синтезаторов речи, например, в Siri, Cortana или Google Translate - строят речь из фрагментов записей настоящего человеческого голоса. Этот метод даёт неплохие результаты, но требует наличия в базе данных записей абсолютно всех звуков речи для каждого используемого голоса. Команда Google DeepMind представила технологию WaveNet, которая требует немного исходного материала, наговорённого человеком, и с помощью глубинного обучения нейросети позволяет генерировать любые слова для данного тембра голоса. Лингвистические правила и рекомендации позволяют WaveNet формировать осмысленную речь (т.е. ИИ понимает смысл того, что он говорит). Однако, разработчики говорят, что в ближайшей перспективе внедрение этого метода в Google Assistant вряд ли возможно из-за огромного объёма требуемых вычислений (WaveNet для синтезирования человеческой речи обрабатывает каждую секунду 16000 образцов аудио).
2013. Видео: Как Siri получила свой голос

Как известно, изначально голосовые способности Apple Siri (распознавание и синтез речи) были реализованы компанией Nuance. В этом ролике вы можете увидеть, как создавался голос Siri (это заняло более 4 месяцев).
2013. Amazon купила лучший синтезатор речи IVONA
Amazon купила польскую компанию IVONA, которая известна своей системой воспроизведения речи. IVONA поддерживает 17 языков и 44 различных голоса. На сайте компании вы можете ввести произвольный отрывок текста и система произнесет его с отличным качеством. Amazon уже некоторое время использовала технологию IVONA в читалках Kindle Fire для воспроизведения книг, но по слухам, Amazon работает над голосовым помощником аля Siri.