Топ 10: Системы распознавания и извлечения данных из документов
Обновлено: 12.02.2026
Машинное обучение позволяет создать нейросети для автоматической классификации отсканированных документов (например, паспортов, прав, обращений клиентов, резюме соискателей) или электронных документов, а также для извлечения структурированных данных из них. Примеры использования распознавания документов для бизнеса приведены ниже.
2022. Microsoft представила платформу ИИ-процессинга данных из документов
Два года назад Microsoft представила сервис SharePoint Syntex, который использует искусственный интеллект для автоматизации извлечения и классификации данных из документов на основе существующих сервисов SharePoint. Теперь этот сервис превратился в самостоятельную платформу Microsoft Syntex, которая содержит набор инструментов для автоматизированного распознавания документов, включая аннотирование файлов и извлечение данных. Syntex считывает, помечает и индексирует содержимое документов (будь то цифровые или физические) и делает эти данные доступным для поиска и использования в приложениях Microsoft 365, а также помогает управлять жизненным циклом данных с помощью инструментов безопасности и архивирования.
2022. Платформа автоматизации политик безопасности Clausematch привлекла $10,8 млн

Стартап Clausematch, развивающий технологии для финансового рынка, поднял раунд финансирования $10,8 млн от фондов Lytical Ventures и Flashpoint. В общей сложности Clausematch уже привлекла около $20 млн. Clausematch в 2012 году основали Евгений Лиходед и Андрей Докучаев. Компания разрабатывает платформу для организации рабочего процесса и совместной работы, предназначенную для оптимизации управления политиками и нормативными изменениями в организации. Платформа компании использует машинное обучение, чтобы помочь отделам нормативно-правового регулирования, юридическим, финансовым, операционным и отделам рисков в автоматизации оценки воздействия, оптимизации внедрения нормативных изменений и совместной работы над документами, позволяя клиентам стандартизировать и автоматизировать внутренние процессы и рабочие процессы между командами, снизить затраты, ускорить внедрение и обеспечить соответствие требованиям. Сейчас стартап дислоцируется в Лондоне.
2020. На Google Cloud появился ИИ-сервис для извлечения данных из документов и форм

Google запустил на своей облачной платформе новый когнитивный API-сервис Document AI, который позволяет автоматически извлекать информацию, содержащуюся в цифровых и печатных документах, с помощью OCR и машинного обучения. Предполагается использование двух процессоров общего назначения, первый - для обычных документов, второй - для анкет/форм. Есть также специализированные процессоры для финансовой документации, например, можно обрабатывать заявки на выдачу ссуд или счета-фактуры. Главными конкурентами Google в этом сегменте являются компания Amazon, которая предлагает подобный сервис Textract на AWS, а также Microsoft со своим инструментом Form Recogniser.
2019. ABBYY запустила сервис распознавания документов в мобильном браузере
Компания ABBYY создала сервис для распознавания изображений документов в мобильном браузере Mobile Web Capture. Он пригодится компаниям, которые используют онлайн формы для получения заявок и заказов от клиентов. Сервис позволяет сэкономить им время - вместо заполнения многочисленных полей, клиент может быстро сосканировать права или паспорт, и сервис распознает данные и заполнит поля самостоятельно. Причем, он легко интегрируется с онлайн формой и работает в мобильном браузере, т.е. пользователю не нужно устанавливать дополнительное приложение.
2019. Amazon выпустила ИИ-альтернативу Abbyy FineReader
Ровно 10 лет назад компания ABBYY запустила онлайн сервис распознавания текста FineReader Online. Теперь подобный сервис есть и у Amazon - Amazon Textract. Однако, прогресс не стоит на месте, и амазоновский сервис уже умеет не только распознавать текст, но и понимать структуру документа (с помощью ИИ). Например, он учитывает и корректно обрабатывает колонтитулы, колонки, таблицы, заполненные формы и даже определяет некоторые форматы данных (имя, номер паспорта, номер социального страхования). Конечно, компанию ABBYY этим не удивить. Они сами собаку съели на технологиях искусственного интеллекта. Их движок уже умеет даже извлекать смысл из документов.
2019. Microsoft представила сервисы для распознавания рукописного текста и заполненных форм
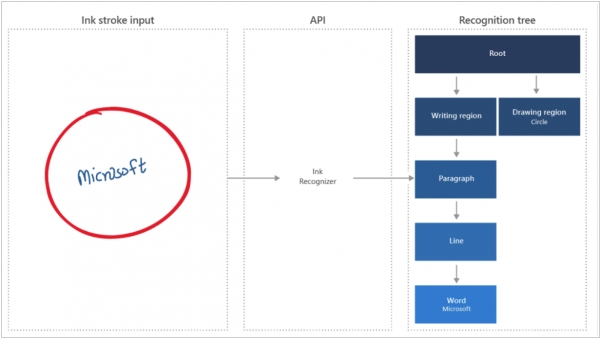
Microsoft представила несколько новых когнитивных сервисов на своей облачной платформе Azure Machine Learning. Во-первых, это подарки для компаний, имеющих дело с документами, формами и служебными записками с рукописным текстом. Сервисы Ink Recognizer и Form Recognizer позволяют переводить все эти бумажки в цифровой текст и данные. Сервис Conversation Transcription - переводит в текст диалоги по телефону с распознаванием автора каждой фразы. К сожалению, это все пока только на английском. Еще один новый сервис Personalizer позволяет подбирать персонализированные рекомендации для посетителей сайта или интернет-магазина на основании поведенческих факторов. Кроме того, Microsoft представила новый визуальный конструктор для создания моделей машинного обучения. Теперь даже маркетологи смогут поиграться. Нужно всего лишь загрузить базу данных и указать, какой параметр требуется спрогнозировать.
2018. Abbyy Finereader научился распознавать смысл документов при помощи ИИ

Компания Abbyy сделала шаг от распознавания буковок и слов к распознаванию смысла сканируемых документов. Зачем это нужно? Чтобы автоматизировать процессы ввода бумажных документов в информационные системы (авто-классификации документов, распознавания полей и таблиц, переноса данных из этих полей в структурированную базу данных). Новый движок ABBYY FineReader Engine 12 умеет это делать с помощью технологий обработки естественного языка и машинного обучения. Конечно, для реализации интеллектуального ввода документов не достаточно просто купить программу FineReader - нужно заказать у Abbyy индивидуальный проект.