Онлайн сервисы для распознавания текста (OCR)
Обновлено: 08.03.2025
Примеры платных и бесплатных облачных сервисов для распознавания текста (OCR) - представлены ниже.
Пользователи, которые искали Онлайн OCR, потом также интересовались следующими продуктами:
См.также: Топ 10: OCR программы
Пользователи, которые искали Онлайн OCR, потом также интересовались следующими продуктами:
См.также: Топ 10: OCR программы
2025. Mistral представил API для умного распознавания PDF
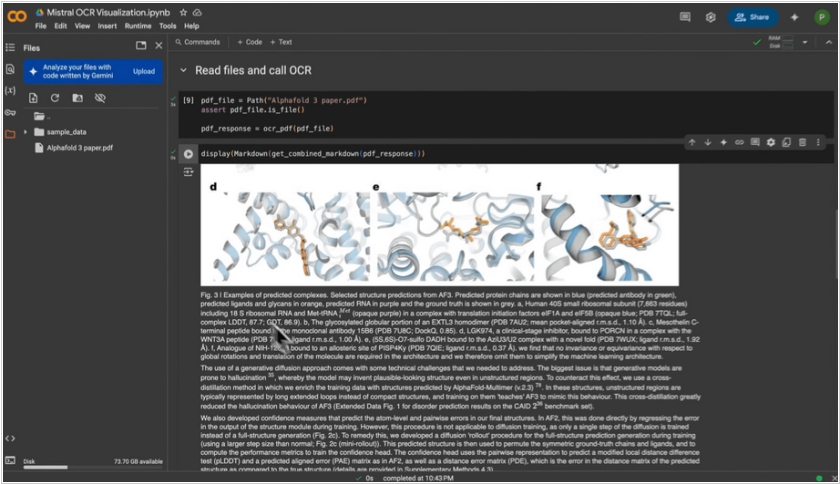
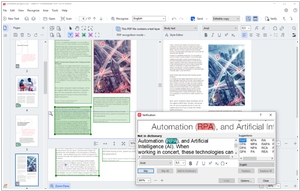
Французский AI гигант Mistral добавил на свою облачную платформу Mistral OCR новый API который позволяет распознавать PDF документы и превращать их в размеченный текстовый формат с изображения, таблицами, формулами и т.д. Как известно, PDF документы имеют разметку, привязанную только к координатам документа, и поэтому даже предложения при переносе строки разделяются в несвязанные блоки. Поэтому для компьютера PDF документ часто выглядит как беспорядочный набор строк и картинок. Новый сервис Mistral OCR создан специально для PDF и умеет связывать текст, отделять картинки и другие элементы. Таким образом, компании могут упорядочить данные, которые у них хранятся в PDF и использовать их в качестве базы знаний.
2020. На Google Cloud появился ИИ-сервис для извлечения данных из документов и форм

Google запустил на своей облачной платформе новый когнитивный API-сервис Document AI, который позволяет автоматически извлекать информацию, содержащуюся в цифровых и печатных документах, с помощью OCR и машинного обучения. Предполагается использование двух процессоров общего назначения, первый - для обычных документов, второй - для анкет/форм. Есть также специализированные процессоры для финансовой документации, например, можно обрабатывать заявки на выдачу ссуд или счета-фактуры. Главными конкурентами Google в этом сегменте являются компания Amazon, которая предлагает подобный сервис Textract на AWS, а также Microsoft со своим инструментом Form Recogniser.
2019. iPhone теперь может преобразовать фото документа в таблицу Excel

В Excel для iOS была добавлена возможность импорта таблиц с помощью камеры. Пользователю достаточно сфотографировать таблицу, Excel самостоятельно распознает данные на фото и конвертирует их в таблицу, которую можно будет редактировать. Кроме того, импортированную с помощью камеры таблицу можно будет потом править в версии Excel для Windows или Mac. Систему можно применять для конвертирования финансовых документов, рабочих графиков, списков задач, расписаний и т. д. Чтобы воспользоваться новой функцией, нужно открыть приложение Excel и нажать кнопку «Вставить данные из изображения». Аналогичная функция для Android было запущена в марте 2019 г. На обеих платформах функция доступна пока только пользователям Office 365.
2019. Amazon выпустила ИИ-альтернативу Abbyy FineReader
Ровно 10 лет назад компания ABBYY запустила онлайн сервис распознавания текста FineReader Online. Теперь подобный сервис есть и у Amazon - Amazon Textract. Однако, прогресс не стоит на месте, и амазоновский сервис уже умеет не только распознавать текст, но и понимать структуру документа (с помощью ИИ). Например, он учитывает и корректно обрабатывает колонтитулы, колонки, таблицы, заполненные формы и даже определяет некоторые форматы данных (имя, номер паспорта, номер социального страхования). Конечно, компанию ABBYY этим не удивить. Они сами собаку съели на технологиях искусственного интеллекта. Их движок уже умеет даже извлекать смысл из документов.
2010. В Google Docs появилось распознавание текста, а в Chrome - PDF ридер
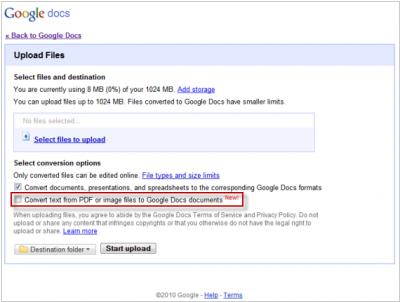
Google добавляет новые инструменты для офисной работы с документами. Во-первых, в Google Docs появилось OCR - оптическое распознавание текста на картинках и PDF-файлах. К сожалению, пока русский не поддерживается (только английский, французский, итальянский, немецкий, испанский), но это лишь вопрос времени. Напомним, в прошлом году онлайн сервис распознования текста FineReader Online запустила и ABBYY (и он понимает русский, но ограничивает по количеству страниц). Во-вторых, в браузере Google Chrome появился встроенный плагин для чтения PDF файлов (его можно включить на странице chrome://plugins). Таким образом, Google последовательно продолжает дружбу с Adobe (после добавления дефолтной поддержки Flash в Chrome).

2009. ABBYY FineReader распознает тексты в онлайне

ABBYY запустил очень полезный и, в то же время, бесполезный онлайн сервис по распознаванию текста FineReader Online. Почему он полезный? Ну как же, теперь, если у вас есть текст на картинке, или в электронной книге, вы можете загрузить файлик на FineReader Online и через некоторое время получить его в текстовом виде. Правда, есть ограничение - 50 страниц на человека в день, но это только на время тестового режима. А почему он бесполезный? Дело в том, что обычно такие вот тексты на картинках представляют собой скриншоты, а их разрешение (как и у электронных книг) - слишком мало для FineReader, поэтому качество распознавания будет ужасное. ***